Building a Data Analyst with OpenWebUI (Part II)
In this previous article, I set myself the goal of replicating the Data Analysis functionality of ChatGPT using Open Source tools. The main advantages of this approach would be that it could entirely be run on-premises, which should help to prevent unintended data leaks, and that it would allow for higher customization and integration with your environment and preferences (programming languages, libraries and data sources, etc...).
The cornerstone of this attempt is the project OpenWebUI which is a llm web interface which can be extended or modified with several abstractions. In the previous article I directly modified the OpenWebUI code and submitted a PR for substituting the way Tools (the abstraction which allow models to run custom functions) are run so they work better in models that have that capability natively. Sadly, it collided with an important refactorization of the tool and wasn't integrated in the main tree, although the maintainer has plans to implement it in the medium term.
But there is an alternative to achieve the same functionality, which is to use another OpenWebUI abstraction called "Pipes". Using them it's possible to exactly tune the way you want the model to behave, including substituting the prompt-based approach for running tools with the native one (all of this is explained in the previous article), without having to modify the project's source code.
So far, what we have is the bare minimum: a tool which can be used by a model to run arbitrary Python code. This code is run in an isolated environment inside docker, and the only means of interaction with the outside is a shared directory, which can be used either for persistence or for providing data to the llm.
Still far from ChatGPT capabilities so let's start adding more features!!
Generating and "seeing" plots
One of the first things I do when presented with a task that requires some reflection about the data is to plot it. Often, initial intuitions can be formed simply by visualizing it.
We have multimodal models now, so there is no reason they shouldn’t be able to do the same.
However, theOpenWebUI "Tool" abstraction doesn’t allow it out of the box, but instead allows to manipulate the “messages” structure directly (if you're familiar with the OpenAI API, you'll recognize this concept).
To check the functionality, I generated a file using the following prompt.
Generate an excel file with 4 sheets, each with a column 500 points.
- first sheet, column labeled "distribution A", which is a mixture of two gaussians, equal standard deviation of 1, but means 0 and 5 (250 points each
- second sheet, column labeled "distribution B", which is an uniform distrbution
- third sheet,column labeled "distribution C" which is a binomial
- fourth sheet, Column Labeled "distributio D" which is a lognormal leave it in the cwd
This was trivial for a llm, let's check how it does trying to recognize the data “by sight”
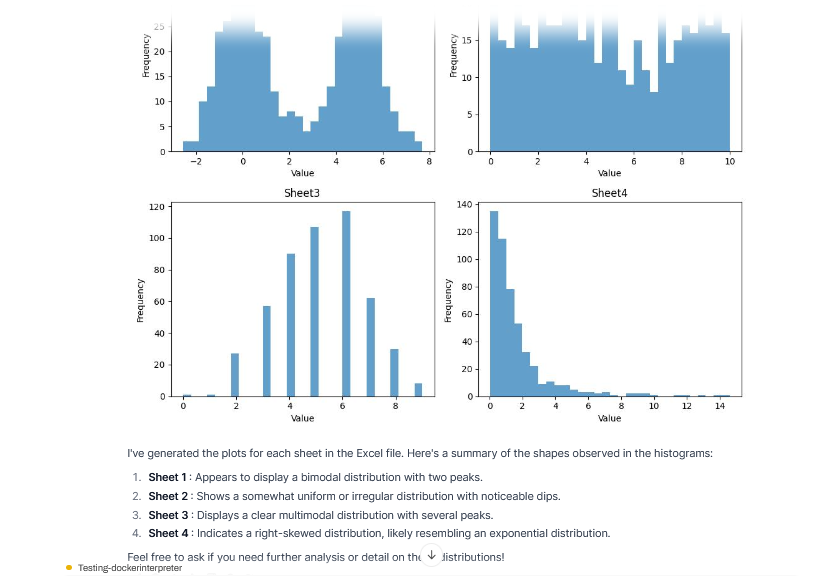
Pretty close! It perfectly guessed sheets A and B. Sheet D one was understandably harder to guess since the exponential and the lognormal look quite similar (in other runs it even noted it was hard to distinguish between the two).
The comment about the distribution C surprised me a bit. I assumed it should be easy to identify, but that's only because I was mistakenly expecting 0 and 1 values in the x axis. But those are characteristic of a Bernouilli distribution, which is just a special case of the Binomial (n=2), and I had misremembered this detail.
Regarless, it’s clear that sheet C represents some sort of categorical distribution, and while the model didn't guess the right statistical process that generated the data points, it is proof that is using its vision capabilities instead of statistical tests or other summary metrics. Something I already knew from reviewing the executed code and its output.
To make this capability truly useful, the model has to be aware that it has this skill, which may require some prompting help. But anyway it is a valuable ability for doing exploratory data analysis.
Adding an R Interpreter
Now that we have a working Python implementation, it should be straightforward to extend the approach to other languages. For a data analysis tool, the obvious next choice is R.
Admittedly I'm not a fan of the language, and once I have to do something more complex than gluing calls together I have a hard time (although since llm's exist, it has become much less painful). That said, I have to admit that coupled with the tidyverse and its %>% operator, exploratory data analysis is much easier and faster, so it makes all the sense to add it to the toolbox.
Equipped with the knowledge of the Python Docker Interpreter implementation, it wasn't hard to build its R counterpart. Let's test it again using the "guess the distribution" test (this time I have asked for a 2x2 grid this time for easier readability).
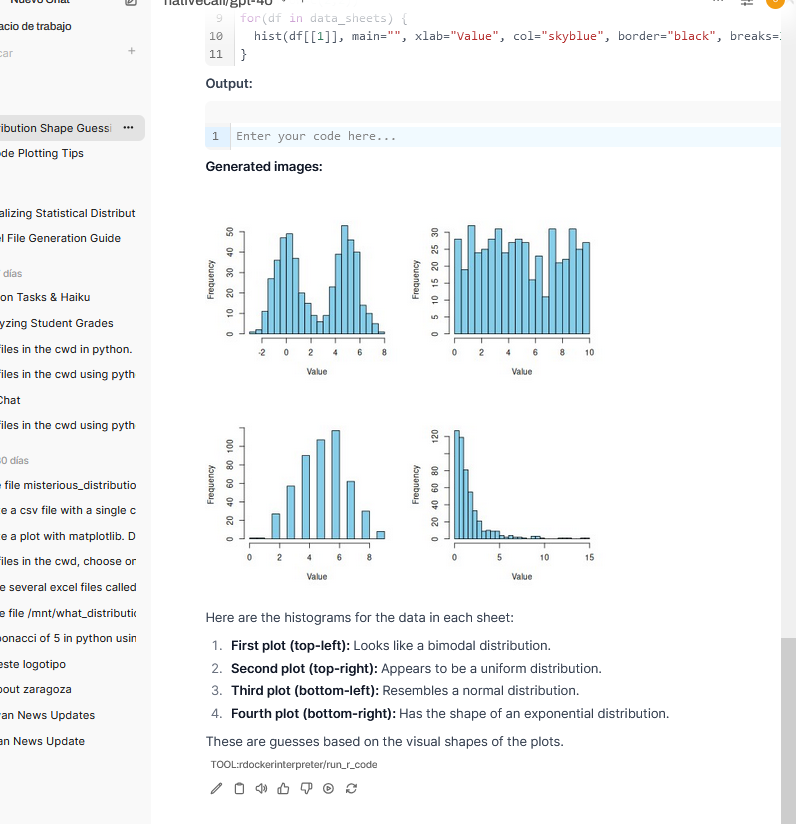
It works great as well, with the same minor inaccuracies which come from "visual" inspection. It feels slightly faster than its Python counterpart, which is rare given that R is typically (even) slower than Python.
One notable advantage of this version is that it should work with any plotting library, not only with a single one like it was the case with matplotlib. Also since R is a language designed for interactive use, it's more verbose over the standard error, which eases makes debugging attempts easier.
Data Manipulation
Providing a model with access to a shared directory already covers a good chunk of data analysis tasks. As easy to load csv or excel files is working with database files such as SQLite or DuckDB is as trivial as dropping the file in the shared folder and letting the model use SQL commands via the standard database libraries the language has available.
But to be really useful, a Data Analyst needs to have direct access to specialized, networked data stores. DataBases, DataWareHouses, Data Marts, Data Lakes... whatever you call them, it usually boils down to having an SQL interface accessible through a TCP connection.
If you have a centralized place to get all the data you need, that's the perfect environment. Pair it with a complete and accurate catalog, and the only thing that's remaining implementation is a way of doing schema discovery and executing SQL.
If you don't have that luxury, you typically will be in the position of wanting to join some data from the SQL Server with a delimited file exported from a legacy system, and 3 other data sources. This might be, and usually is, boring enough for a human, but workable. But a model doesn't have (for now) the ability to manipulate GUI tools, manage different sets of credentials, install database drivers, etc... so it's much more important for them to have available a single and unified interface to the different data sources, which is the only point of contact with networked data.
There are some tools which provide that functionality (although, to my surprise, none of them is targeted to the desktop user) which will allow us to emulate the "single datastore" scenario. The Big Data community has produced at least a couple: Presto/Trino and Apache Drill. They are initially designed to perform distributed queries over different data stores without the overhead of consolidating all data in a single place, but will be usable also in scenarios like this one.
Both Presto/Trino and Apache Drill may act as DataBase "proxies" enabling the use of a single SQL dialect across different backends. Apache Drill also may be connected to unstructured data sources, like csv files, mongo collections, etc... in addition to relational databases (as long as they have a JDBC driver, which all, even the most obscure database, offers nowadays).
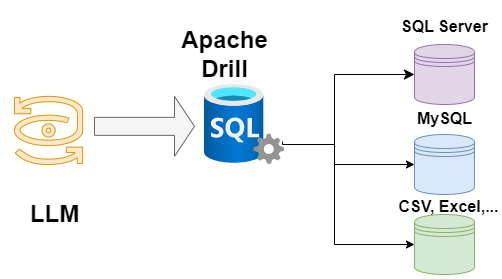

Apache Drill also comes with a really easy to use REST API, so I decided to implement the "browsing and exploring" functionality using it.
It turned out to be a big mistake, as Drill doesn't live up to its promises. SQL dialects are far apart enough to need specific tuning/translation from the SQL one that Drill implements. You just can't rely on JDBC and expect things to work. The reality is that there are a handful of "first tier" implementations (MySQL, SQL Server, etc...) and everything outside that is unsupported (even SQLite, the most deployed database in the world, doesn't perform poorly).
If that’s not enough, client support outside Java is pretty bad. Probably Trino would have been a much better implementation choice. But at this time I was too invested in this approach to change it. It’s still good enough to show the functionality, so I stuck with it.
So what this layer has to provide are these features:
"Data Browsing" as in:a way to navigate the namespace (database->schema->table)a way to get metadata (column names and types, etc..)
Query cost estimation to avoid overloading the data store (angry DBAs blaming the LLM is something to avoid).
An SQL shell to run arbitrary queries (with a limit, we don't want to burn too many tokens with unbounded queries)
An easy way of letting Python and R retrieve the data.
Data browsing is pretty hard to get right: too much information and you will overload your context limit, too little and you will need to perform dozens of calls for retrieving metadata. But again, this project is just a proof of concept so I ended up implementing the simplest possible solution.
To test the setup, I loaded a Wine quality dataset with two tables and connected it as a storage backend for Apache Drill. Let’s see if it can answer some questions.
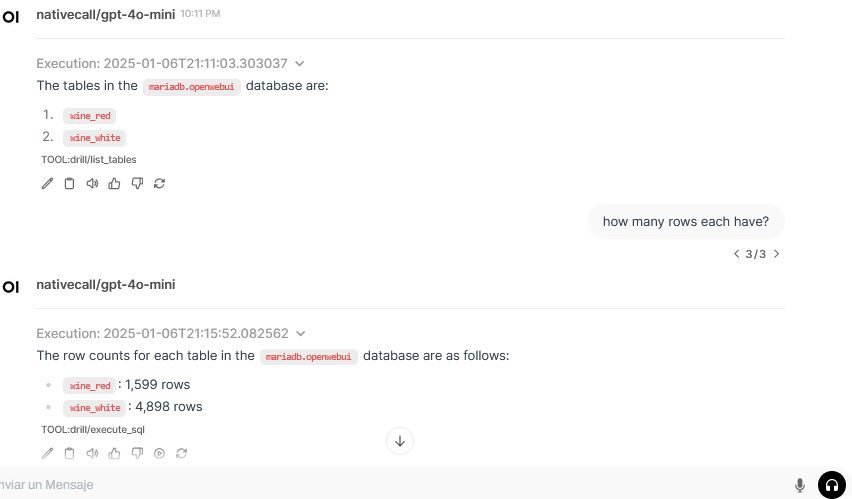
After developing and enabling this tool, we can see it can browse the catalog and run SQL queries.
Putting all together
Now we have a “data analyst buddy” that has the ability of running code, it can query the same data as you, and type at lightning speed!.. However it also suffers from amnesia and occasionally tries to gaslight you. It has to be instructed about how to connect to the data source with the Code Tool each time, and keeps repeating the same dumb mistakes, like re-reading the same metadata each time, etc...
All of this can be mitigated by employing a system prompt, in which the rules for effectively using the tools and the general guidelines about how to conduct the data analysis may be defined. This takes time and a bit of patience, but with every addition to it the model gets a bit better and more usable.
For instance, sometimes the model will assume the code tools are stateful, and will try to use the functions defined in previous executions. Warning about it will prevent, to a certain degree, from repeating the mistake again.
It’s also a good practice to keep a project specific prompt, in which to keep the information which is relevant to the current problem at hand.
With that idea in mind, sharpening the tools takes time and care, we can test the solution by posing an open ended question, asking the model to predict of the quality of the wine based on the rest of parameters. The prompt:
Under mariadb.openwebui there are two tables which contain parameters of certains kinds of wine (red and white). Each row is a differente wine.
You can explore the dataset using the data oriented functions, but retrieving data is limited to 100 rows, so outside of aggregation queries, don't rely on it to retrieve data.
For that, you can use the R interpreter, loading the data into tibbles using this code
library(sergeant)
dc <- drill_connection("172.18.1.95")
# result is a tibble
data_tbl <- drill_query(dc, "select * from <table>")
With that in mind, could you do some classification to predict the quality score of the wine (0-10) based on the rest of variables?
Starting with this point, during the conversation:
The schema gets analyzed by the llm. The variables identified and the data loaded in R data frames.
Starts with a decision tree for classification treating quality as discrete.
Discusses the suitability of switching to a regression model (quality is 0-10).
Performs the linear regression.
Hallucinates a variable selection step.
Performs the variable selection when signaled that actually didn’t run the code.
etc..
You can download the complete example from here.
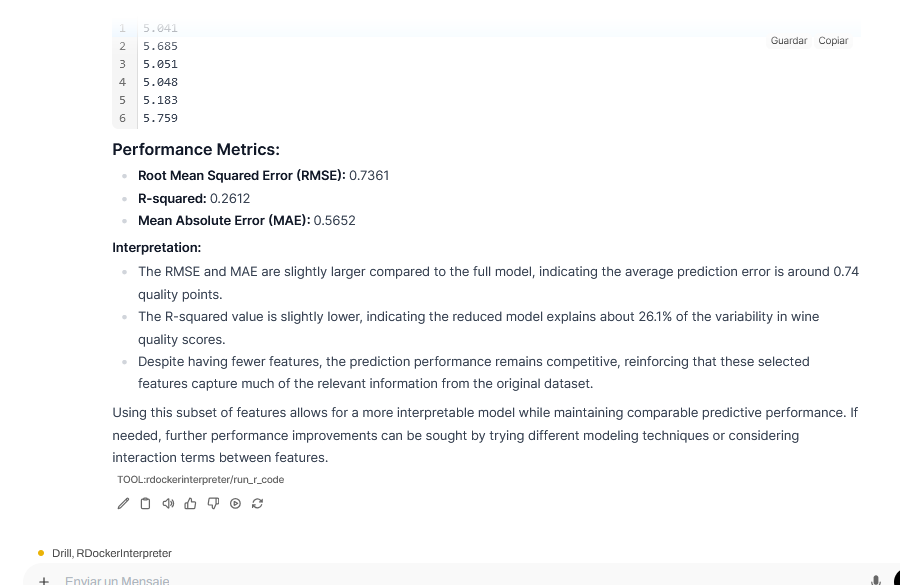
I am just showing a bit of the exchange, but you can see that with a bit of back and forth it’s easy and quick to get a prediction model or make useful plots. The model makes a lot of failed attempts accounting for up to 8-10 tool calls at times, but that’s the whole point.
4o-mini which is my default go-to model (it’s fast and cheap) doesn’t go very far, it requires a lot of direction, but 4o on the other hand, does pretty well, although it doesn’t fit my definition of cheap. Other models look promising, but haven’t had the time to find a good wine which is multimodal, supports tools and it’s cheap.
Conclusion and next steps
As the saying goes, when a project is 90% complete, only the other 90% remains😅
Creating something useful for oneself is one thing; making it useful for others is an entirely different challenge. The first goal is definitely achieved: I have successfully used this solution to solve a few small problems. And I hope I have also convinced you that the second one is within reach.
Admittedly the journey hasn’t been so smooth. I have conducted a lot of tests and changes, and I have cherry picked the best responses for the article.
Anyway, this is the worst it's going to be. I will keep refining the solution, and the first thing I plan to do is to replace the Apache Drill layer with a better alternative. Frankly, I should have done this already, but I had planned to publish the article by the end of the Christmas holidays (marked in Spain by the Three Kings’ day on January 6th), and I missed that deadline already!
I hope someone has made this far! If that’s the case, thanks for reading.
You can find the code here: https://github.com/smonux/open-webui-docker-execution
Acknowledgements
Thanks to Timothy Jaeryang Baek for his incredible work in creating and maintaining OpenWeb UI. If you use OpenWebUI in your company please consider donating or sponsoring him

Comments
Post a Comment