Building a Data Analyst with OpenWebUI (Part I)
The "Advanced Data Analysis" is my favorite ChatGPT feature. It's one of those features that, once you see it for the first time, the mind can't stop imagining the possibilities it provides. An LLM which can not only generate code but it is able to run and iterate over it! It's simply amazing.
But at the same time, it's impossible not to realize its limitations. It runs in some kind of sandbox (apparently based on Google's gVisor), with an ephemeral filesystem and no Internet connection. What if I want to install a new package? Or give it access to my Data Warehouse instead of using simple csv files? What if I prefer R over Python? etc...
(Now I know much of these use cases could be implemented using GPT Actions, but when I learnt about it I was too invested about the OpenWebUI approach. This is probably true also for other approaches, that provide the functionality without so much hassle.)
So, when I discovered OpenWebUI, an LLM front-end with extensibility capabilities, my first reaction was to try to replicate the functionality. How hard could it be, right?
Well, actually, it's not that easy.
This is the account of my troubles trying to build something that resembles to the actual thing. If not an actual clone, at least something inspired by it and that's useful. Despite it limitations, a local implementation would inherently have some advantages over ChatGPT's implementation:
It would be completely hackable, every component could be modified or inspected.
It could be run completely on-premises. That's not my case (I'm GPU poor), but there is possible, and it's a quite solid choice for a privacy conscious company.
A bit of warning: This is not a HOW-TO as much as a collection of thoughts and impressions of what I have learnt I found worth sharing. But replicating it shouldn't be hard.
If you aren't that interested about the low level details, you can skip to the conclusion and business case sections at the end. May be you could still get some insight from those sections.
Hope you find it interesting!

The tools
The tools required for building the functionality are:
Docker: Once you know docker, it's hard to think about the time before you did. It allows for instantaneous experimentation, painless installation and deployment, and, something that's more important for this project, dynamic allocation of isolated runtime environments (aka containers).
OpenRouter.ai: Not strictly required, but a great addition and a must have for everyone who likes to play with models without breaking the bank. Having an OpenAI API key for experimentation it's great, but soon you will want to try one of those amazing models you read about in r/LocalLLama.... but you live in an apartment, happily married, and all the space in your house it's efficiently allocated for storage: clothes, toys, books, etc...Given that building a big, noisy multi-U server equipped with several GeForces it's not an option for you, what can be done?
OpenRouter solves it by giving access to almost any LLM provider in existence with a single endpoint and API key. They provide an OpenAI compatible URL, and switching from GPT4o to Claude, Mistral or Llama it's a one-line change. You can also find amazing models available for pennies and with its load balancing capabilities, it is also great for production use.
Ollama: This is the alternative in case you actually have a capable GPU. It allows to very easily download and run open models, providing:
- a command line interface
- an API for remotely running prompts, which is pretty capable (supports streaming)
I have just used it with very small models like llama3B to test the compatibility of the implementation, but it's a great project and very important in the llm-tinkerer space.
Hetzner: This is not really a tool, but a cloud provider, still 8GB VPS for 8 eur/mo it's really a bargain and something to write about. It is an excellent option to run pet projects like this, much easier than playing with home RPI's and tunnels as I have seen people deploying for their projects. That's not worth the hassle (unless you want it to be).
OpenWebUI: This is the main element of the stack and it could suffice to say that's a ChatGPT clone. A web app where you can talk (quite literally since supports voice) to almost any bare bones model which exposes an API to the outside. What makes it interesting are its extensibility features, although they can be somewhat confusing for newcomers. Without going into details about the different options that it provides, things are possible are:
- modifying requests and responses, for example, to remove Personal Information from prompts (using small local models or "traditional" NLP techniques) before is sent to the cloud.
- implement custom RAG Pipelines over proprietary or sensitive data.
- modify the UI to implement custom actions (buttons, etc...)
- etc..
The most interesting of them in my opinion is what is called simply "Tools" which allows to implement functions in python which are immediately available to the model. It then may follow the approach proposed in the famous ReaAct paper. OpenWebUI does all the behind the screens work, and the developer just has to implement the functions it wants to make available to the model.
The project is really impressive, especially when you learn that is a one-man's work. Still, it suffers from the common maladies of open source projects that lack of enterprise and financial support. It has lots of functionalities, but some of them don't work always reliably and predictably, documentation is lacking or outdated, etc...
Still, for nerds which aren't afraid to look into the source code it's a great project to work with, and very fun to hack.
The Goals
Building a data analyst it's a bit of an ill-defined goal, right? What traits should it have to be really useful? Well, at least these ones:
Statistical and data wrangling knowledge
Programming skills (R and/or Python)
Access to interpreters and runtimes.
Data explorng capabilitites.
Some kind of "perseverance" or resourcefulness. The ability to see the bigger picture and work hard to achieve it.
1 and 2 should be provided by models. Due the formal and predictable nature of math, they tend to be pretty good on both, even smaller ones. Those are a given.
5 is probably the hardest to define and attain and the reason everyone is working on agents. Here we aren't looking for such a complex behavior here, but a bit of perseverance is required. If the result wouldn't be satisfying, it would be still improvable by advanced prompting techniques.
So, 3 and 4 are our homework. Easy!!
The Code Interpreter
Running code is one of the first things someone would want to do with an agentic LLM, but blindly running the code it produces doesn't seem to be a great idea.. I I have read accounts of people giving bash shells to models with catastrophic results. So we need some kind of isolation for safety and resource control.
The most simplistic idea is to try to restrict the libraries and primitives the LLM produces before eval'ing it, combining prompting with checks to ensure that the generated code doesn't violate the restrictions. This can be done at the source code level or at the bytecode one using python's ast library.
It's a viable hack also a dead end. As soon you give it filesystem access to the model almost any bad outcome is possible, which makes viable only very algorithmic use cases.
Other approach is go for OpenAI's solution in ChatGPT, which we know it's based in Google's gVisor. This is what this tool does and it's probably the most popular form of running code from OpenWebUI at the moment. The way it works is by running directly the runtime component of gVisor "runsc", which follows the Open Container Initiative specification.
This is fine, but there's an alternative but similar approach, which is to use Docker's API directly to create and run the scripts inside containers. I decide to take that route instead and develop my own tool. This way is a bit more flexible and the exact runtime implementation is just a matter of configuring it inside docker. In a typical "on-premises" environment which doesn't require to spin thousands of containers probably is not worth to switch from the docker default's runc, which gives better performance and better compatibility.
Python has an easy to use docker package, which is also by default installed on OpenWebUI's default image. It gives the ability to further configure the parameters of the containers trough a dockerfile, which also allows us to configure a "shared" folder from which the model can read and write files persistently, something we will ease the use of the Data Analyst. Adding RAM and CPU constrains and disabling network connection are also some sane defaults I decided to add it (although it's configurable).
This configuration certainly won't contain SkyNet, but it will avoid a dumb LLM from thrashing the filesystem or clogging the server that runs OpenWebUI.
The main drawback is that OpenWebUI has to have write access to the docker socket (let it be local or remote), but again, this as secure as you want the infrastructure to be. In an enterprise implementation, you will want to isolate this docker host from your regular workloads.
So let's check it!

Not bad. The model has run the code and we also can see the input and the output. I have instructed it in the system prompt not to repeat the code and the output by informing it that he tool gives us the ability to see them, so it's less verbose.
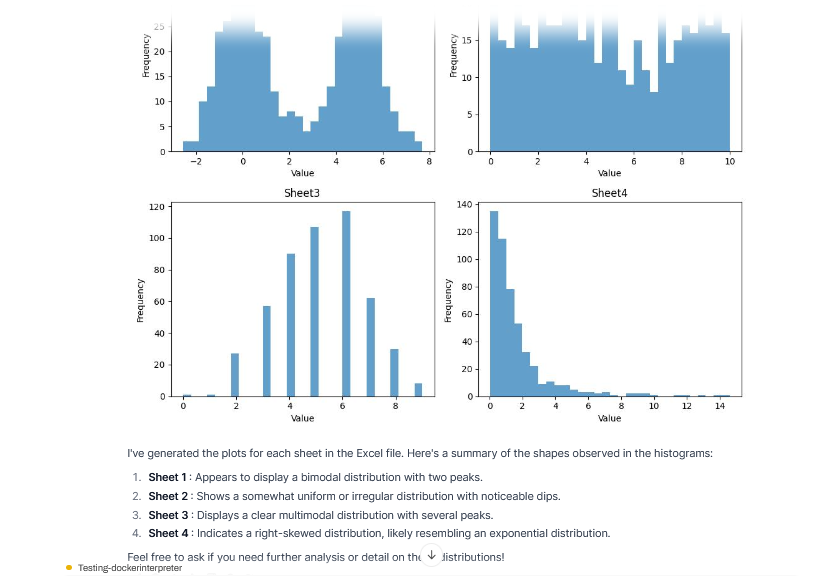
Let's try something more challenging: reading some excel files and processing them to guess what statistical distribution follows the data:

This is a bit unsatisfying. The model has generated a sintactically incorrect file (this is rare but may happen), but it hasn't tried to correct it's mistake and redo again. This kind of behavior is consistent among attempts, no matter the prompt or the model, which is very different from the functionality works in ChatGPT.
The only way forward at this point is to look into the code and try to find an explanation.
Native function calling vs Prompt based
The reason that the models were having so little initiative is the way the Tools are implemented in OpenWebUI by default.
(Here I'm going to basically to summarize what's explained in this excellent article).
There are two forms of implementing tool calling.
Prompt based function calling, which is no different of regular "structured outputs" requests. You want the llm choose a tool call, and produce the request with some data with a specific format, so you make a prompt for that, and then dump the output in the context, not unlike is done with typical RAG approaches.
The other is called "native" in which the model has some specific tokens in its vocabulary dedicated to signaling tool related actions: here it comes a a tool specification, a tool call starts, etc... The LLM is trained with thousands of examples that use those token, so it learns to produce them with ease.
A leaderboard exists to compare how good current models are in this regard (hint, proprietary ones tend to be way better, which I attribute to the fact they have been fine tuned for agent building use cases).
As you would expect, the second one is much more versatile. The model will naturally "decide" to perform a tool call mid sentence, for example.
But, there is also an important drawback. Weaker models haven't been trained for tool calling and for lots of use cases the prompt-based approach is enough and more reliable so it makes sense to have that option as a default.
Still, a proper Data Analysis implementation will want to have the more advanced version, so the only option is to integrate it into the OpenWebUI core as an optional feature. This has taken me a bit more effort than I was planning, and has made to raise my Python game, but after spending some hours and fixing lots of bugs fixed I got a working implementation.
The result is and additional parameter, which can be turned on per model or globally to switch between implementations. Sadly there is not a reliable way to tell if a model will support tools and in the case it doesn't it will fail silently.

I have also tried to merge this feature into OpenWebUI, but my Pull Request hasn't been accepted still (nor rejected). I hope it gets merged at some point of the future because I think it's a nice feature that other people may benefit from.
Anyway! We have a working implementation to play with. Let's try again the "guess the distribution" prompt.

(Warning: This is a hand picked example, it doesn't always behave this way, but it's much more sucessful than before.)
As we can see, the model is now much more resourceful! This time, it executed up to 5 different scrips to complete its goal, correcting its mistakes and interleaving executions with text generation.

Next Steps
Ok, after some months I reached the point I expected to be in two weeks most.
Admittedly, which is a pretty typical delay for software projects 😅
But the implementation, despite being useful as it is (for me at still), still lacks lot's of the things I wanted it to have: language choice, graph display, data discoverability, etc...
It's an interesting challenge and fun to hack so my intention is to continue working on it, and writing about it, although I can predict how much it will take it (I have family and a job after all).
One thing I have become convinced to by playing with the React approach is that "traditional" RAG, in which the data lookup is performed outside the LLM is harder to
The business case
I can't avoid ranting a bit about my disappointment because the lack of deployment of AI chat interfaces in the enterprise.
Just recently I received a email from my employer warning about the dangers of sharing internal data with cloud providers: Dropbox, Gmail and.... ChatGPT. I understand the warning about the two first ones: they provide alternatives to the other two (also cloud based, but still), but there is none for the last one.
Do we really think that people who have learned to use llm's are going to stop using it just because a warning like that? These early adopters, the most curious and resourceful in your company, who have realized this is at least internet-level technology... are they going to give up to the productivity gains it produces? Not likely.
Consider for example the following prompt:
create a excel document using openxyl which contains data of several students with their grades and personal information, and bar chart which shows sex ratio at every grade level (A, B, C,etc..) Lets assume there are 25 individuals and equal number of boys and girls
This zero-shot prompt generates a whole excel file which fits the requirements (this is Anthropic's "weak" model Haiku, BTW). It's not hard to extrapolate it to common office tasks.

From 0 to 10, how revolutionary do you think is for the average office worker? Not less that an 8 if you ask me: I myself would struggle a solid half to an hour with Excel to get that result (not an spreadseets wizard by a long shot, but most people aren't either). I also believe that no more of 10-20% of such workers know that's even possible.
While products like MS Copilot are surely impressive, there is no need to spend +20eur/month per worker to get a good chunk of their benefits . A chat interface to a 30 to 70B model which may cost realisticallly as low like 0.10 input- 0.30 output (per million tokens). Coupled with the proper training: what are hallucinations, how to prompt effectively, etc... the productivity gains in the office might be massive.
Running it in your own GPU's probably make it a bit more expensive and way more complex, but the control about your data in that scenario is complete, something which may be very tempting for some companies.
So, why don't we hear about massive deployments of chat interfaces in the enterprise world? At least, I don't. May be I do live in a bubble and most companies have already adopted an strategy in this field. I would love to hear about it, if that's the case.
What I see instead it's a lot of fuss about worker replacement, almost magical agents, etc... while the obvious use case it's right there before our eyes.
A last bit of warning. May be OpenWebUI isn't the exact technology in which base your efforts. Despite its impressiveness it still has some rough edges, and I wouldn't try to make a project based on it without strong Python coders at the team. From I see in the forums people is starting to deploy it company wilde with some success, but do your research first.
Acknowledgements
Thanks to Timothy Jaeryang Baek for his incredible work in creating and maintaining OpenWeb UI. If you use OpenWebUI in your company please consider donating or sponsoring him
Comments
Post a Comment